A DNS a jövő adathordozója?

A felhő korában, amikor szinte minden levelünk, képünk, dokumentumunk távoli, misztikus szervereken lakik, természetesnek tűnne, hogy valóban, bizonyítottan ez a fajta adattárolás legyen az általunk ismert legmegbízhatóbb.
A valóságban azonban nem ez, mégpedig azon praktikus szempontból, hogy a felhő-alapú adattárolás egyszerűen nem létezik elég régen ahhoz, hogy ilyen jellegű kijelentést tehessünk. Ahogy a flash memória esetében is maximum évtizedes adatmegőrzési képességet tudunk igazolni, a mágnesszalagoknál több évtizedest, a bakelitlemezeknél pedig durván évszázadost. De akkor mi a komplex adatok tárolásának bizonyítottan legtartósabb módja? A papír (és rokonai) esetében is párezer éves a legrégebbi ismert (töredékes) példány, és ha még régebbre akarunk menni, akkor már a kőtáblák, vagy még jobban visszapörgetve az idő kerekét, barlangrajzok korába jutunk.
A spanyol El Castillo barlang kézlenyomatai és nonfiguratív ábrái közel 40 ezer évvel ezelőtt születtek, és ha elfogadjuk ezek információhordozó-jellegét, akkor ésszerűnek tűnhet ezeket a korabeli ábrákat, pontosabban az őket tartalmazó felületeket tekinteni a legősibb információhordozónak.
A valóság azonban az, hogy nagyságrendileg is régebbiek azok a komplex információk, amelyeket a mai technológiával megbízhatóan meg tudunk határozni, és ezekben az esetekben a bizonyítottan jól működő információhordozó közel sem egy sziklafal szürkeségű élettelen anyag, hanem maga a DNS: közel 430 ezer éves emberi csontokból is tudtunk már használható DNS-szekvenciát kiszedni, és az abszolút rekord jelenleg közel 700 ezer éves csontokból származó DNS szekvenálása. (Megjegyzendő, hogy ezeknél régebbi leletekről is szólnak néha cikkek, de azokat a szekvenciákat a kutatók többsége inkább modern szennyeződésnek tulajdonítja, mint valódi ősi DNS-nek.)
A DNS-ben levő információra a „tervrajz” és „program” analógiát szoktuk használni, amelyek egyike sem tökéletes körbeírása az örökítőanyagnak, de annyira mindenesetre pontosak, hogy jól láthassuk, valóban komplex információhordozó a dezoxiribonukleinsav.
A DNS egyik nagy előnye, hogy általában a biológiai mintákban „felszaporított” állapotban van, vagyis nem egyetlen kópiában, hanem akár több százban is, ami egyfajta természetes minőségbiztosítást ad, hiszen ha egy-egy molekulában ilyen-olyan okból meg is jelenne valamilyen mutáció, valószínűtlen, hogy az az összes többi kópiában ugyanott jelen legyen, vagyis elég sok DNS megszekvenálásakor (szakzsargonban „megfelelő mélységű” szekvenálás esetén) az ilyen hibák könnyen kiszúrhatók és a sok molekula szekvenciájának átlaga már a helyes információt hordozza majd.
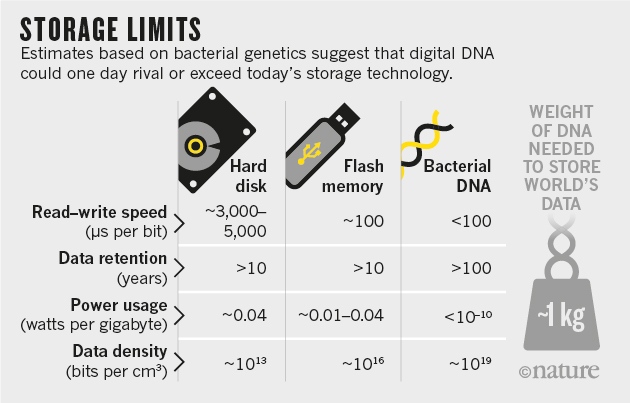
Mindez nyilván rendkívül vonzó információhordozóvá teszi más, szintetikus adatok felhasználásának szempontjából is a DNS-t és ami miatt már (még ?) nincsenek a boltokban a DNS-alapú adathorodozók, az két technológiai megkötés: egyrészt ugyan sokat gyorsultak (és nagyon olcsóvá váltak) a szekvenálási technológiák az elmúlt években (tulajdonképpen a Moore-törvényt meghaladó dologról van szó), még mindig nem kompetitívek sebesség szempontjából a klasszikus random-access memóriákkal összevetve. Ennél is nagyobb gond azonban, hogy az új DNS-szálak szintetizálásának költsége egyáltalán nem követte eleddig a szekvenálási költségeket, vagyis nem vált irtózatosan olcsóvá a dolog.
Éppen ezért jelenleg inkább csak hosszútávú információhordozóként jön számításba a DNS, igaz, ebből a szempontból egyre vonzóbb, különösen az új kódolási algoritmusok megjelenésével.
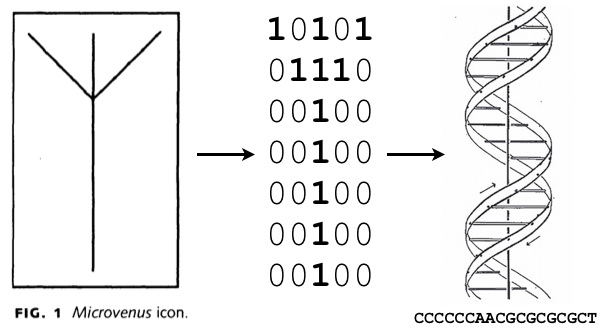
Az első próbálkozások a DNS-be kódolással nem sokkal a rekombináns DNS technológia megjelenése (vagyis a DNS-darabok viszonylag szabad kombinálásának kidolgozása) után feltűntek. A legelső ilyen jellegű próbálkozás azonban nem egy genetikushoz vagy informatikushoz kötődik, hanem egy művészhez: 1988-ban Joe Davis, részben a SETI-program keretében kiküldött arecibói üzenet hatására az életet szimbolizáló ősgermán rúnát kódolta át előbb 35 bites digitális üzenetté, majd egy 18 bázispár hosszúságú nukleotidszekvenciává. Ez természetesen akkor érdekes próbálkozásnak tűnt, de igazából művészi önkifejeződésen kívül még nem sok ember látott bele bármit is.
A huszonegyedik század második évtizedének elején aztán felgyorsultak az események. Előbb az első „szintetikus élőlényt” előállító Craig Venter kódolt bele egy Mycobacterium genomba, amolyan easter-eggként pár külön jelentéssel bíró szekvenciát (kb. 8000 bit mennyiségben), majd 2012-ben, a szintetikus biológia másik fenegyerekének, George Churchnek a csoportja 5.27 megabitnyi információt (Church Regenesis: How Synthetic Biology Will Reinvent Nature and Ourselves című - 53,426 szó hosszúságú - könyvét, 11 JPG formátumú képet és egy JavaScript programot ) tárolt sikeresen DNS-szekvencia formájában. És innentől kezdve mindenki számára nyilvánvaló volt, hogy a DNS tényleg szintetikus információ-tárolóvá válhat. A DNS-es adattárolás mennyiségi rekordját a University of Washington és a Microsoft kutatói tartják, akik 200 megányi adatot tudtak sikeresen eltárolni DNS-ben, majd hiba nélkül visszaolvasni.

Ez utóbbi teljesítmény a korábban már említett természetes hiba-biztosítás ellenére nem triviális. Hogy mennyire nem az, azt jól mutatja, hogy ma már klasszikusnak számító munkájukban Churchék 22 hibát is találtak a visszaolvasás után, ami már kellően megbízhatatlanná tenné a DNS-alapú információhordozást. Ennek leküzdésére mára már számos kódolási algoritmust bevetnek a digitális információ szekvenciasorozattá való átalakításakor, ezért úgy tűnik, ilyen jellegű akadálya nem lesz majd a DNS-alapú információhordozók elterjedésének.
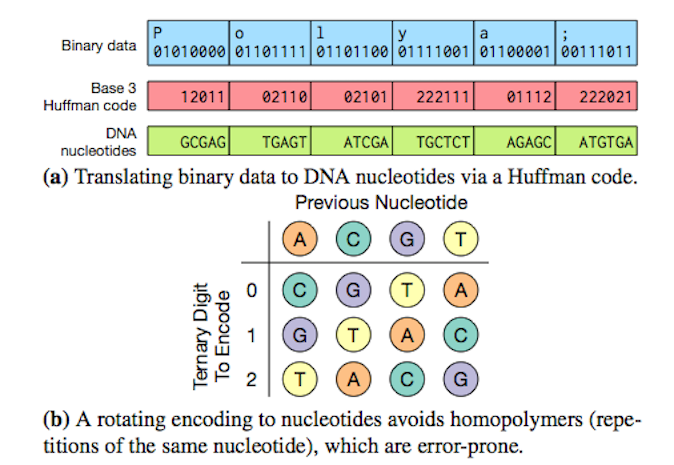
Mivel a DNS szekvenciája négyféle bázispárból áll, ez lehetőséget ad arra, hogy a bináris, digitális információ átkódolásakor számos olyan trükköt alkalmazzunk, hogy az egymás után következő bázisok ne egyszerűen egyetlen bitről hordozzanak információt. Lehetőség van arra, hogy egymás utáni bázisok a korábbi nukleotidokról is hordozzanak valamilyen információt, illetve arra is vigyáznak ma már az ilyen szekvenciák tervezésekor, hogy kerüljék azokat a szekvenciákat, amelyek a természetben könnyebben mutációk megjelenéséhez vezetnének (pl. nukleotid-ismétlődéseket). Rengeteg, az IT világában rendszeresen használt kódolási stratégiát sikerült már DNS-re átülteni, kezdve a Huffman-kódolástól (lásd itt), a Luby Transform szökőkút-algoritmuson át (itt) egészen a Microsoft említett, legújabb cikkében bevetett Reed-Solomon-féle hibajavító kódokig.
Ezeknek az újításoknak köszönhetően pedig nemcsak lényegesen megnőtt a biztonságosan tárolható (és relatív könnyen és olcsón visszanyerhető) adat mennyisége, de lényegesen tömörebbé is vált: jelenleg 214 Pbyte/gramm környékén járunk, ami sok nagyságrenddel hatékonyabb eljárást jelent, mint a klasszikus merevlemezeknél, vagy flash-alapú adathordozóknál.
Erre a tömörségre márpedig minden jel szerint a nem is annyira távoli jövőben szükségünk lehet. Jelenlegi növekedési trendek mellett a tárolandó digitális információ mennyisége 2020-ra eléri a 44 trillió gigabájtot (GB), 2040-re pedig már ott tartunk majd, hogy ha egyszerre akarnánk mindenféle információt flash-memorián tárolni, akkor azok előállításához közel százszor több nagytisztaságú sziliciumra lenne szükségünk, mint amit a jelenlegi chipkészítő kapacitás biztosítani tud.
Nem véletlen, hogy a Microsoft is egyre komolyabban foglalkozik a DNS-alapú adattárolással, és komoly tervei vannak, hogy a közeljövőben bizonyos hosszú-távú adattárolást már DNS-alapú felhőben végezzen.
Mindez persze sok szempontból a jéghegy csúcsa lehet és bizonyos DNS-alapú tárolási eljárások még épp csak születőben vannak. Erre enged legalábbis következtetni az aktuális Nature-ben megjelent cikk, ahol – ki más, mint – George Church csapata egy videó képeit szekvenciálisan kódolta be egy baktérium-populáció genomjába.
A korában leírtak fényében talán érthetetlen lehet, hogy miért olyan nagy szám 2017 nyarán, ha Eadweard Muybridge klasszikus mozgó lovas videójának öt képkockára lebutított változatát DNS-be kódolják, de itt nem az információ-mennyisége, hanem a bevitel mikéntje keltett méltán feltűnést.
A „bakteriális immunrendszerként” CRISPR/Cas9 rendszerről, mint az újgenerációs genomszerkesztés legfőbb eszközéről már írtam korábban. Csak míg a genomszerkesztési eljárásoknál a rendszernek azt a tulajdonságát használták ki, hogy a DNS-hasítás helyét programozni lehet, az új cikkben egy teljesen másik tulajdonságra került a hangsúly: hogy a rendszer valamennyire adaptív is. Ez egészen tömören azt jelenti, hogy ha egy bakteriális vírus, azaz egy fág megtámadja a sejtet, és az sikeresen túléli a támadást, akkor a DNS-ének egy szakasza beépül a bakteriális genomba és a jövőben, egy új támadáskor már aktívan irányítja a nukleázokat a fág-DNS elhasítására. Ezek a kis szekvenciadarabok rövid spacer szekvenciákkal elválasztva kerülnek bele a genomba és az új szekvenciák mindig a sor végére lesznek beillesztve. Vagyis a sejt belső rendszere már maga tudja az időbeliséget kezelni.
Az egyetlen probléma, hogy a rendszer csak kb. 20 bázispáros szekvenciadarabokat tud kezelni, márpedig értelemszerűen ennyi információ, még a legcsodálatosabb tömörítéssel is édeskevés egy képkocka kódolásához. Így ebben az esetben Churchék arra támaszkodtak, hogy nem egyetlen sejtet, hanem egy teljes bakteriális populációt transzformáltak egy olyan DNS-egyveleggel, ahol egy-egy képkocka információja 20 bázisos, átfedő információ-kvantumokra lett szétosztva. Így annak ellenére, hogy egyetlen sejt csak egy kis részét tartalmazta az adott képkockának, a populáció egésze a teljes információt hordozta. A folyamatot ötször megismételve a populáció összessége, szekvenciálisan (a spacerekkel elválasztva) mind az öt képkocka információját hordozni fogja és visszaszekvenálva ezeket az adaptív genom-darabokat, az átfedéseknek köszönhetően, megfelelő algoritmusokkal mind az öt képkocka vissznyerhető (kisebb hibákkal, lásd a fenti Giphy jobb oldalát).
Ugyan a módszer ötletesnek tűnik, azért persze felmerül a kérdés, hogy ha már más eljárásokkal 200 MB-t tudunk kódolni, akkor vajon mi szükség van erre a körülményes kódoló eljárásra? Hát nem videó-kódolásra érdemes használni, az tuti, és a konkrét tanulmány is inkább nagyon ötletes PR-fogásként alkalmazta a Muybridge videót, hogy bebizonyítsa, elvileg élő sejtekkel is lehet szekvenciálisan információt kódolni.
És ugyan itt még konkrétan bakteriális sejtekről van szó, a középtávú terv, hogy valamiképpen eukarióta sejtekben (pl. idegsejtekben) is hasonló dolgot hozzanak létre, ami potenciálisan lehetővé tenné, hogy egy sejt az élete során különböző időpontokban fontos információkat írjon bele a genomjába, amit később kinyerhetünk. Ez pedig egy minőségileg új lehetőséget jelentene azokban a kísérletekben, ahol egy sejt élete alatt bekövetkező változásokat próbáljuk nem invazív módon követni.

De persze nem ez az egyetlen dolog, ami miatt a DNS és a kódolás még hosszú ideig az érdeklődés középpontjában marad. Hiszen minden erőfeszítésünk ellenére a mai napig elég keveset tudunk arró, hogy egy-egy sejt miképpen éri el, és kapcsolja be vagy ki a megfelelő pillanatban a sejtmagjában levő sokmillió bázispárnyi genom megfelelő részét. Ez azonban egy másik történet.
(Forrás: Nature, megint Nature és Scientific American.)